Hello AI, I Am Julia

Julia for data visualization
A few friends and former students who are working as programmers have told me recently that I should write about Julia. Julia is not a person but a language. One person called this "the new Python" while another said it was the "Python killer."
Python is the so-far-unchallenged leader of AI programming languages and is used by almost 90% of data scientists, but it is probably not the future of machine learning. Programming languages, like all languages, fall out of favor and sometimes die. There is not much demand for the COBOL, FORTRAN and BASIC that was being taught when I was an undergrad.
Julia is faster than Python because it is designed to quickly implement the math concepts like linear algebra and matrix representations. It is an open source project with more than a thousand contributors and is available under the MIT license with the source code available on GitHub.
I have learned that you don’t need to know programming to do some AI. There are no-code AI tools like Obviously.AI, but programming is necessary for some devlopment.
The home site for Julia is julialang.org which has a lot of information.
An article I read at pub.towardsai.net led me to investiagte a free online course on computational thinking at MIT that is taught using Julia.
This is not a course on programming with Julia but almost all data and AI courses are taught in Python (perhaps a few using R and other languages) so this is unique as a course. The course itself uses as its topic the spread of COVID-19.and includes topics on analyzing COVID-19 data, modeling exponential growth, probability, random walk models, characterizing variability, optimization and fitting to data. Through this topic the course teaches how to understand and model exponential functions. That has much broader application into financial markets, compound interest, population growth, inflation, Moore’s Law, etc.
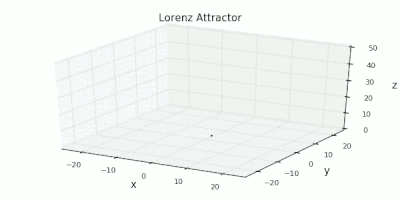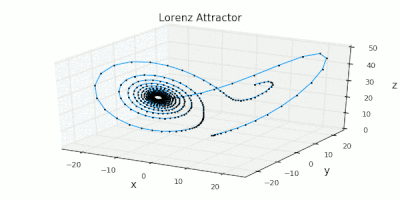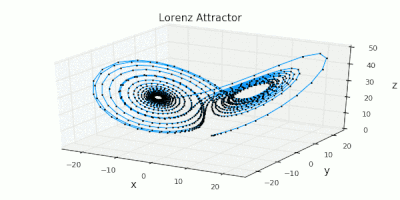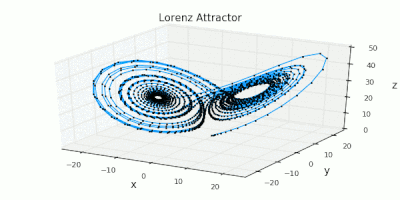
Julia used for scientific computing
As that article notes, right now searching jobs on LinkedIn for “Python Developer” will turn up about 23,000 results, so there is a market for that skill set now. Searching “Julia Developer” will return few results now. You can find a LinkedIn group for Julia developers, called “The Julia Language,” so interest is there and the jobs are beginning to appear. A Julia specialits now has a big advantage in that there are fewer people with that skillset for the jobs that are appearing. The predictions (always a dangerous thing) are that Julia has a big role to play in the data & AI industry.

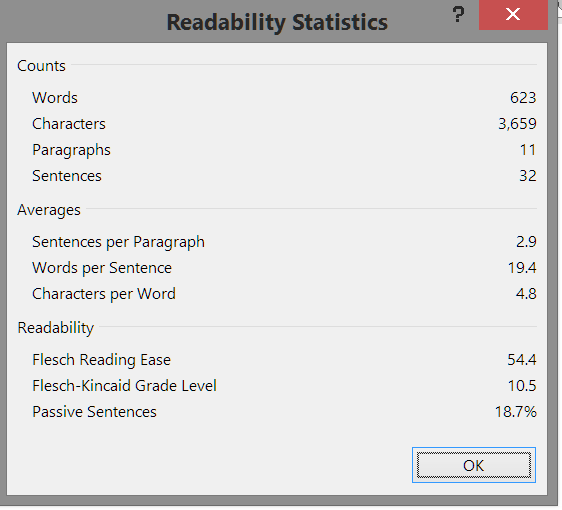 You might think that score seems to be low for a post I am aiming at educators, but many sources will recommend that ease of reading in order to boost your numbers and even
You might think that score seems to be low for a post I am aiming at educators, but many sources will recommend that ease of reading in order to boost your numbers and even 

